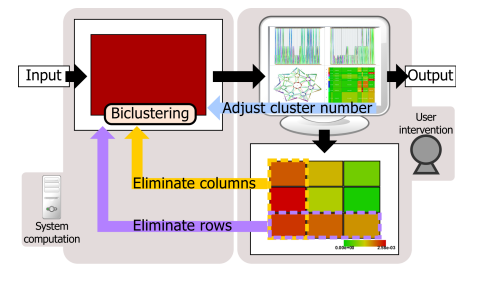
Datasets obtained through recently advanced measurement techniques tend to possess a large number of dimensions. This leads to explosively increasing computation costs for analyzing such datasets, thus making formulation and verification of scientific hypotheses very difficult. Therefore, an efficient approach to identifying feature subspaces of target datasets, that is, the subspaces of dimension variables or subsets of the data samples, is required to describe the essence hidden in the original dataset. This paper proposes a visual data mining framework for supporting semiautomatic data analysis that builds upon asymmetric biclustering to explore highly correlated feature subspaces. For this purpose, a variant of parallel coordinate plots, many-to-many parallel coordinate plots, is extended to visually assist appropriate selections of feature subspaces as well as to avoid intrinsic visual clutter. In this framework, biclustering is applied to dimension variables and data samples of the dataset simultaneously and asymmetrically. A set of variable axes are projected to a single composite axis while data samples between two consecutive variable axes are bundled using polygonal strips. This makes the visualization method scalable and enables it to play a key role in the framework. The effectiveness of the proposed framework has been empirically proven, and it is remarkably useful for many-to-many parallel coordinate plots.

0 Comments