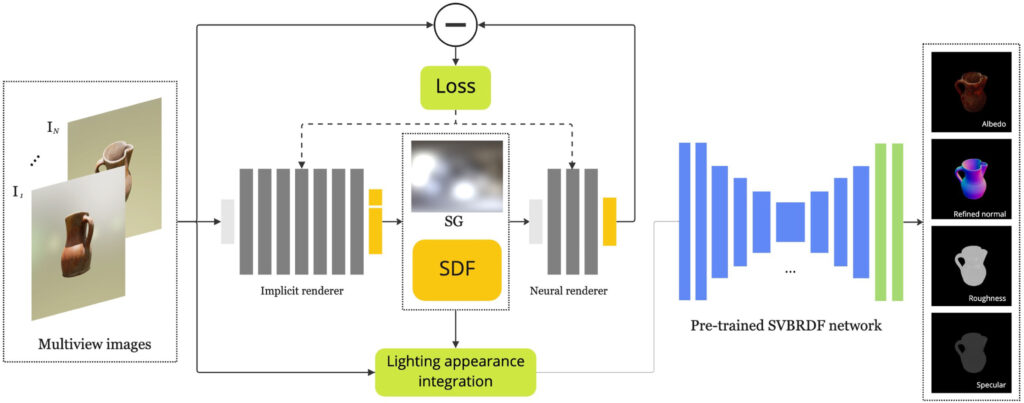
This paper proposes a stable method for reconstructing spatially varying appearances (SVBRDFs) from multiview images captured under casual lighting conditions. Unlike flat surface capture methods, ours can be applied to surfaces with complex silhouettes. The proposed method takes multiview images as inputs and outputs a unified SVBRDF estimation. We generated a large-scale dataset containing the multiview images, SVBRDFs, and lighting appearance of vast synthetic objects to train a two-stream hierarchical U-Net for SVBRDF estimation that is integrated into a differentiable rendering network for surface appearance reconstruction. In comparison with state-of-the-art approaches, our method produces SVBRDFs with lower biases for more casually captured images.


0件のコメント