概要
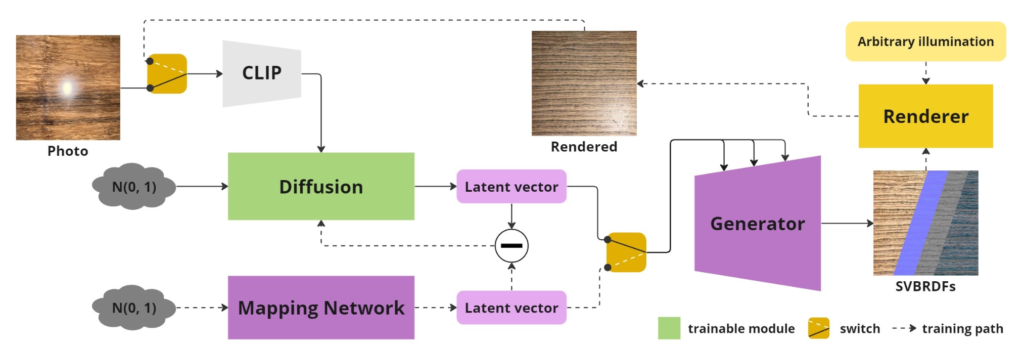
3次元(3D)コンテンツの創作において,写実的なマテリアルの生成は,視覚的な現実感と没入感を大幅に向上させる点で必要不可欠である.この作業は従来,多大な手作業を必要としていたが,写真からマテリアルを再構成する近年の研究は有力な代替手段を提供した.これらの方法はデータ駆動型であり,深層ニューラルネットワークを利用した自動化により,処理は革命的に簡単化された.しかしその進歩にもかかわらず,殆どの関連技法は制御 された照明条件を必要とし,さまざまな実世界環境で撮影された写真から直接的にマテリアルを作成することは未だ難しい.この課題を解決することは,3次元デジタルマテリアルの生成にとってきわめて重要である. 本研究では,写実的レンダリングのさまざまな分野に対応するマテリアルの推定および合成のための新しい方法を導入する.Contrastive Language-Image Pre-training(CLIP)画像エンコーダに,さまざまな照明下の画像から潜在空間におけるマテリアルを生成する多層クロス・アテンションのノイズ除去ネットワークを組み合わせている.DiffMatは,幅広い物理ベースのレンダリングパイプライン に統合するように設計され,最新のアプローチと比較しても,DiffMatはより高品質なマテリアルを生成し,参照画像に関係する制約も少ない.
メンバ
| 名前 | 現在の所属 | ホームページ |
|---|---|---|
| 慶應義塾大学 | ||
| Yan Dingkun | 東京工業大学 | |
| 斎藤 豪 | 東京工業大学 | https://www.img.cs.titech.ac.jp/ |
業績
論文誌
- Liang Yuan, Dingkun Yan, Suguru Saito, Issei Fujishiro: “DiffMat: Latent Diffusion Models for Image-Guided Material Generation,” Visual Informatics, Vol. 8, No. 1, pp.6–14, March 30, 2024 [doi: DOI].
資金
 基盤研究 (A):21H04916 (2021)
基盤研究 (A):21H04916 (2021)